Every search engine crawling bot first interacts with a website’s robots.txt file and its crawling rules. This means that the robots.txt file plays a pivotal role in the Blogger blog’s search engine optimization (SEO). This article will guide you on how to create a well-optimized custom robots.txt file for Blogger and how to understand the implications of blocked pages reported by Google Search Console.
What are the functions of the robots.txt file?
The robots.txt file tells the search engine which pages should and shouldn’t be crawled. This allows us to control the crawling of all web spiders. In the robots.txt file, we can control the crawling activity of each user-agent by allowing or disallowing them. We can also declare sitemaps of our website for search engines like Google, Bing, Yandex, etc. So that these search engines can easily find and index our content.

The function of robots meta tags is to control page level indexation i.e. page should be visible in search result or not.
Usually, we use the robots meta tags to index or noindex blog posts, pages, and other format web content throughout the web. And the robots.txt to control the search engine bots. You can allow the complete website to crawl, but it will exhaust the crawling budget of the website. To save the crawling budget of the website, you have to block the website’s search, archive, and label sections.
The robots meta tag is page level and used to decide whether a web page should be visible in SERP. Additionally, a file called robots.txt helps control how search engine bots should behave on the website. If we let the bots freely crawl through our entire website, it could use up a lot of resources. To manage this, we can use robots.txt to tell the bots not to crawl certain parts, like search, archive, and label sections. This way, we save resources and ensure the bots focus on the important stuff on our website.
Default Robots.txt file of the Blogger Blog.
To optimize the robots.txt file for a Blogger blog, we first need to understand the CMS structure and analyze the default robots.txt file. Default robots.txt file of Blogger-
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://www.example.com/sitemap.xml- The first line (User-Agent) of this file declares the bot type. Here it’s Google AdSense, which is disallowed to none(declared in 2nd line). That means the AdSense ads can appear throughout the website.
- The following user agent is *, which means all the search engine bots are disallowed to /search pages. That means disallowing all search and label pages(same URL structure).
- And allow tag to define that all pages other than the disallowing section can be crawled.
- The following line contains a post sitemap for the Blogger blog.
This is an almost perfect file to control the search engine bots and provide instructions for pages to crawl or not crawl. But this file allows for indexing the archive pages, which can cause a duplicate content issue. That means it will create junk for the Blogger’s blog.
Optimizing Robots.txt File for a Blogger Blog
We understood how the default robots.txt file performs its function for the Blogger blog. Let’s optimize it for the best SEO.
The default robots.txt allows the archive to index, which causes the duplicate content issue. We can prevent this issue by stopping the bots from crawling the archive section. For this, /search* will disable crawling of all search and label pages.
Applying a Disallow rule /20* into the robots.txt file will stop the crawling of archive sections. The /20* rule will block the crawling of all posts, so to avoid this, we have to apply a new Allow rule for the /*.html section that allows the bots to crawl posts and pages.
The default sitemap includes posts, not pages. So you have to add a sitemap for pages located under https://example.blogspot.com/sitemap-pages.xml or https://www.example.com/sitemap-pages.xml for the custom domain. You can submit Blogger sitemaps to Google Search Console for good results.
So, the new perfect custom robots.txt file for the Blogger blog will look like this.
User-agent: Mediapartners-Google
Disallow:
User-agent: * # to select all crawling bots and search engines
Disallow: /search* # to block all user generated query item within the website.
Disallow: /20* # this line will disallow archieve section of Blogger.
Disallow: /feeds* # this line will disallow feeds. Read instruction below
Allow: /*.html # allow all post and pages of the blog
#sitemap of the blog
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap-pages.xml- /search* will disable crawling of all search and label pages.
- Apply a Disallow rule /20* into the robots.txt file to stop the crawling of archive sections.
- Disallow: /feeds* this rule will disallow crawlers to crawl the feed section. But if you are not generated new Blogger XML sitemap then do not use this line.
- The /20* rule will block the crawling of all posts, So to avoid this, we’ve to apply a new Allow rule for the /*.html section that allows the bots to crawl posts and pages.
In the above file, the setting is the best robots.txt practice for SEO. This will save the website’s crawling budget and help the Blogger blog to appear in the search results. You have to write SEO-friendly content to appear in the search results.
Effects in Search Engine Console after implementing these rules in robots.txt
It’s important to note that Google Search Console may report that some pages are blocked by your robots.txt file. However, it’s crucial to check which pages are blocked. Are they content pages or search or archive pages? We can’t display search and archive pages, which is why these pages are blocked.
But if you want to allow bots to crawl the complete website, then you have to configure robots meta tag and robots.txt file in such a way that.
- Robots.txt file allows crawlers to crawl the whole website.
- Robots Meta tag disallows non-important pages to noindex.
The amalgamation of Blogger robots.txt and robots meta tags may exhaust the crawling budget, but the better alternative is to boost the SEO of the Blogger blog.
How do you implement this Robots.txt File to Blogger?
The Robots.txt file is located at the root level of the website. There is no access to the root in Blogger, so how do you edit this robots.txt file? You can access root files like robots.txt under the settings section of Blogger.
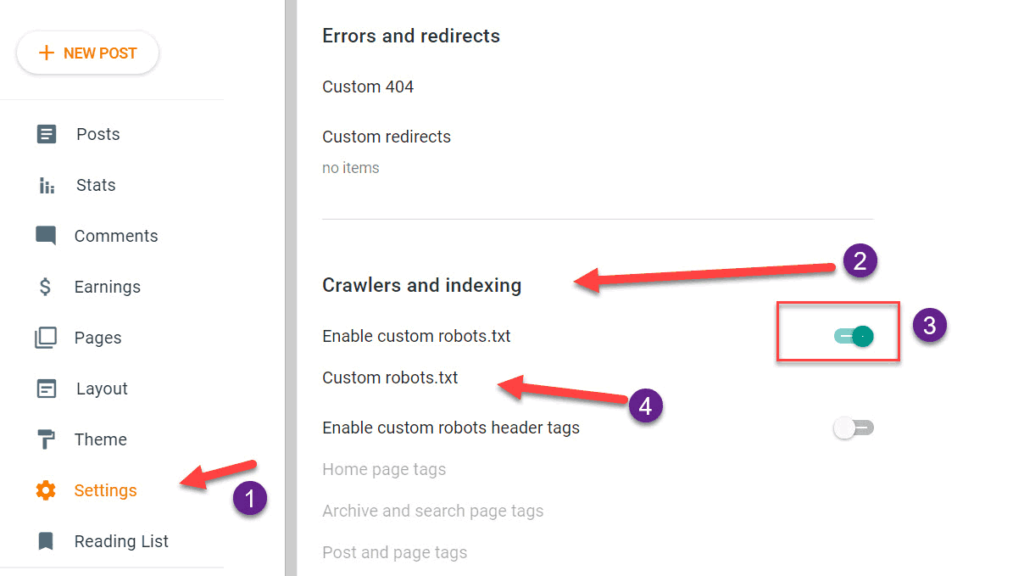
- Go to Blogger Dashboard and click on the settings option,
- Scroll down to the crawlers and indexing section,
- Enable custom robots.txt by the switch button.
- Click on custom robots.txt; a window will open. Paste the robots.txt file and update.
After updating the custom robots.txt file for the Blogger blog, you can check the changes by visiting your domain like https://www.example.com/robots.txt, where www.example.com should be replaced with your domain address.
Conclusion.
We’ve explored the function of the robots.txt file and created an optimal custom robots.txt file for the Blogger blog. In the default robots.txt file, the archive section is also allowed to crawl, which causes duplicate content issues for the search engine. This confusion can lead to Google not considering any Page for the search results.
Remember, Google Search Console may report blocked pages, but it’s crucial to understand which pages are blocked and why. This understanding will help you optimize your site for better SEO results.
I hope you found this article helpful. If you have any doubts or questions regarding Blogger or WordPress SEO, feel free to comment below.
Thank you for this awaesome posts or blog i have added this in my 3 blogs.
1. OpenWorld TechInfos
2. Gurutechnical90
AND
3. TechPro MaxInfo
Once again thank you very very much.
I came here through YouTube your video was showing at the top how did you make that can you make the blog of it please.
Is it possible to block links indexed with (/? M = 1), because my site that is indexed by the search engine is the mobile (/?m=1)
That will not be good for the SEO of the Blogger Blog. You must configure your blog in Google Search Console. Read this article for the best practice. Solve Blogger m=1 issue/
?m=1
Thanks for the article, this helped me a lot. Top SEO Pakistan
Please check out my site www.tubenybangers.com I need seo advice
i have submit custom robots.txt file according to you but yet
there is an error and ranking of site is going down continuously
if you have any solution then please provide
Follow best practice of robots meta and robots text. Link provided in this article
Thanks, bro. It was a very helpful blog especially for new bloggers I appreciate your hard work well-done Bro.
You have made this tutorial very easy to understand for your readers as a blogger I impressed from your writing skills and from your sound knowledge keep going and best of luck for your future posts
Thanks Abdul 🙂
Thanks for the article, this helped me a lot
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://www.xyz.blogspot.com/sitemap.xml
Vs
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://xyz.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
Which one is best for fast indexing and seo friendly robots.txt please explain?
sitemap.xml is proper sitemap addition method.. you don’t need to update it after, say 500 posts or 1000 post . It contain all post sitemap in it.. you can add page sitemap too..
Where atom feed a kind of rss feed. That’s not a proper sitemap method.
So, second one is not good your saying
2nd one is wrong method.. ok if you think 2nd method is perfect method, then how you can add pages sitemap with that?
No I don’t know properly that’s iam asking you second one is generated through famous sitemap generator tool called as labnol.org finally thankyou so much for replying
The method discussed in this article is right one, other one is wrong method brother. You can try submitting both kind of sitemap to Google search console..
You’ll see you’ve to add only 2 sitemaps- one for all pages, and one for all posts(no matter how many pages or posts you’ve).
And for atom feed(labnol) you’ve to add sitemap for every 500 posts, if you’ve 3000 blog posts then you’ve to submit 6 sitemaps, and there is no any sitemap for pages..
Currently I am using below mentioned sitemap. When i change it on robots.txt file then should I update it on google search console also?
https://onlinesweaterstudy.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
I advise you to follow https://seoneurons.com/en/blogger-seo/xml-sitemap/
Thanks and Regards.
Sir, My name is Ravi and I start a Hindi news website with my friends. I want Google Adsense approval. So, suggest us the SCO required for my website and what we need to improve in website. Also, Suggest us best SCO friendly Blogger Template for Hindi news website.
Thanks so much for this article! I found it extremely helpful.
Thank You So Much For This Valuable Information.
I haven’t seen this kind of knowledge regarding SEO.
You are genius sir.
Thank a lot again.
Sir I have to submit both sitemaps in Search Console?
Yes, one sitemap of all pages and other is for all posts.
I am facing one more issue in blogger.
My search description is not visible in Search Results.
It’s showing random text..
Please let me know how to make it perfect.
thanks for explaining but question Why didn’t you activate the feature enable custom robots header tags
https://seoneurons.com/en/blogger-seo/custom-robots-header-tags-seo/ Follow this article to get the detailed answer.
Disallow: /20*
What is Disallow: /20* in robots.txt?
We already explain this in the article. It will block all the archive sections for the crawling bots to address the thin content issues. We can also perform this action by using noindex such content. But for that, read the meta tag and robots.txt combination (link provided in the last paragraph of this article).
Hi Ashok Hw r u ? First of all I would like to appreciate you that you are guiding the bloggers in regards of best technical seo settings. But I am facing problem during use of the above given custom robots.txt file , when we use this format then it does not fetch all blog blog pages or posts in bing or in other search console. For example if we have 100 posts in blog then in bing it only fetching 2 or 3 posts by using sitemap.xml but if we use atom.xml then it fetch more but for that we have to change your custom robots.txt format. Give us a best solution ?
One more thing if we add above custom robots.txt setting in blogger settings then is it mandatory to use this setting in just below of the theme html section ? As many bloggers are using paid blogger templates & they have no idea if their template providers have already installed such codes or not ? As all are not technically sound in coding and all , therefore your website viewer will trust on your call . Please guide to all in best way what they should do , so that they could get benefit from your given seo settings . Also guide viewers about ” Home page tags” Archives & search page tags” Post & Pages tags” settings if anyone use above given code of Custom robots.txt settings . is mandatory to use both codes ?
could you please reply on my last query ? Since we updated given custom robots.txt file into our blog , it is not fetching our all blog pages into google search console or other search console. What is the solution of this ?
There are two solutions.
first is blocking search engines access to all thin content and allowing indexing of Pages and posts. (This post explain that)
And
2nd is allowing access of search engine to all thin content but noindex them in robots meta tag, allowing only indexing of Pages and Posts. (Combination of robots meta tag and robots.txt for blogger, find the link in the last paragraph.
You can follow any of these two. Thanks
Obrigado mais fiquei um pouco confuso nos comentários
Thanks You very much sir. You are great. i read many article so i comment here..
1. thanks for understanding schama [i appllied in blogspot] – webmaster tool enhance yahoooooo
2. thanks for m=1 for understanding [in the blogger market lots of faked post about it] but u understand clear about it.
3. thanks for custome robots.txt
Regars iliyas shaikh
hello blogger expert i need help my this https://kaomojihub.blogspot.com/ blogspot issue in sitemap i am submit my sitemap but showing two types of error 1. urlset Missing XML tag
how to fixing this issue please tell us
Hi Ashok,
Recently I have disabled made my custom robots.txt and custom robots header tags and since then my website ranking is falling like anything. Earlier my website used to get 1000+ daily views which got decreased to 100+. I don’t know what went wrong all of the sudden. Can you please let me know if I really need a custom robot and custom robots header tag? If yes, can you please help me to get the perfect robots.txt and header tag settings for my website. Following are the details:
– website: http://www.dharmsansar.com
– hosted on: Blogger
– Current (default) robots.txt:
———————————————
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://www.dharmsansar.com/sitemap.xml
————————————————————-
– Earlier custom robots.txt:
——————————————-
User-agent: *
Disallow: /search/
Disallow: /tags/
Disallow: /category/
Disallow:/p/
Disallow: /search/label/
Allow: /
Sitemap: https://www.dharmsansar.com/sitemap.xml
Sitemap: https://www.dharmsansar.com/sitemap-pages.xml
——————————————–
– current “enable customer header tags”: disabled (default)
– earlier “enable customer header tags”:
homepage tags: all, nodp
archive and search index tags: noindex, nodp
post and page tags: all, nodp
Thanks in advance!
Regards,
Nilabh
I think you can find your answers here https://seoneurons.com/en/blogger/default-theme-why-you-should-not-use/
Sir, I also want to know which is best between both robot.txt provided by Nilabh
with custom robots.txt file you were blocking the page section to crawl.
Disallow : /p/ means directories under /p/ will be blocked, that is not a right practice
Thank you for this post. I am going to use what I have read on my blogger blog which is >>
my blog is there running with custom robots txt https://offblogmedia.blogspot.com
Please bro help me finally.
Step A :/CUTOM ROBOT.TXT//////////
===========================
1. User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap:
https://www.xyz.blogspot.com/sitemap.xml2. User-agent: *
Allow: /
Sitemap:
https://www.xyz.com/sitemap.xmlSitemap:
https://www.xyz.com/sitemap-pages.xmlSTep B :Custom robot header txt :////////
=====================
What is the perfect settings for custom robot header tags for avouding all type of issues and errors related or caused by robot.txt/sitemap/ and others…..
• Home page
• Archieve and search pages
• Default post and pages
Hello Md Jakir, you can try https://seoneurons.com/en/blogger-seo/robots-txt-and-robots-meta-tags-for-seo/ to avoid all types of errors.
thanks great post
Thanks for this really appreciate it
Hi, It was really great & helpful, I have applied It For my website. Thanks a lot.
I think you are not only blocking the archives with this settings, you are also blocking the mobile versions (?m=1):
User-agent: *
Disallow: /search*
Disallow: /20*
Allow: /*.html
You should use something like this instead (see the last line):
User-agent: *
Disallow: /search*
Disallow: /20*
Allow: /*.html*
The current robots.txt is working fine and not blocking ?m=1. Please check with robots.txt Google Testing Tool.
can I use the code you have mention in you article robots and robots meta with this configuration
Thank you for this! I’ve been having issues with my blog not being indexed nor crawled. And search results dont show.
This was the text I got and pasted on the custom robots txt:
# Blogger Sitemap created on Wed, 29 Jun 2022 12:38:38 GMT
# Sitemap built with
https://www.labnol.org/blogger/sitemapUser-agent: *
User-agent: *
Disallow: /search
Disallow: /category/
Disallow: /tag/
Allow: /
Sitemap:
https://example.com/atom.xml?redirect=false&start-index=1&max-results=500I’m changing that today and copying the code here. thanks so much!
india memang beda, dulu arvin gupta MyWabBlog
In most blogger themes, we customize menu items using labels and the generated URLs like the one below:
example.com/search/label/tech
The URL structure in the above example is as follows: search > label > tech > articles
When you block or disallow the /search in robots.txt, both the label, menu items, and subsequent articles are immediately blocked from indexing.
Optimizing your site’s labels for crawlers is good SEO practice as it allows the search engines understand your content. Unfortunately, when /search is disabled, you cannot index the labels (and the content below the labels?).
What are your thoughts on this? Is there anything I’m missing here?
This is to avoid duplicate content issues. So it is better to avoid indexing search pages.
thanks so much this really help.
sir I’m new to blogger i have done everything that i knew.
i have uploaded my first 5 posts and none of them are indexed.
there came a pop up with 2 problems
1-Discovered – currently not indexed
2- Alternate page with proper canonical tag
Sir it’s my humble request to please help me with something that can solve my problem
1. Please create more unique content.
2. This problem is with Blogger, as there is different URLs for mobile and desktop
Hello, is it possible to /disallow the crawl of images on a specific /p/
…?
Best regards great blog
Hello
I have a stupid question
is changing from robots.txt to another and update it will not cause any problem to my Blogg !
Also if I change robots.txt in my blogger is there other changes I need to add in google search console
this is my website please support me :
https://www.nafsiyatokasihatoka.com/
Visit this website for best and latest mobiles tips & tricks https://www.blogger.com/blog/posts/40255920498749906
Sir, should we use tags in blog posts? Does using tags hurt SEO?
CRAWLING AND INDEXING
Page is blocked from indexing
Search engines are unable to include your pages in search results if they don’t have permission to crawl them. Learn more about crawler directives.
Blocking Directive Source
/robots.txt:4:0
Very helpful. I looked for this answer for many years but i guess your work is set in the search engine just like you have thought. I have applied it and it does even make my page load very fast. Thanks you’re genius
nice
Thank you for this, it helped my https://proboostr.com website.
Crowlers and indexing should always be open
Hello!!!
Thank you for the post! I’ve found it very helpful.
The issue I have is that the sitemap generated it have the urls with “http” like “http://www.example.com” but I did the redirection to “https”.
Then Google Search Console it says that any page of the sitemap is indexed as it does not find them.
I have configured HTTPS availability on blogger but not the https redirection as I’m using cloudflare DNS.
Any idea how can I fix this? It will be much appreciated!
Thanks!
hello sir
I have some indexing issues and and I would like to know if this configuration works well :
User-agent: Mediapartners-Google
Disallow:
#below lines control all search engines, and blocks all search, archieve and allow all blog posts and pages.
User-agent: *
Disallow: /search*
Disallow: /20*
Allow: /*.html
#sitemap of the blog
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap-pages.xml
on blogger settings
Enable custom header tags for robots
is it correct this configuration?
Home page tag = all, noodp
Search and archive pages tag= noindex, noodp
Post and pages tag= all, noodp
I also enabled the redirect domain
examplte.com – to – www.example.com
thanks
best regard
Hello.
I am. Having redirect error and canonical tags problem in my indexing. What to do now
dear bro.
2k posts in my blogger site, so i write my robot txt like as below. my ques. is it ok or wrong?
——-
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://mydomain.blogspot.com/sitemap.xml
Sitemap: https://mydomain.blogspot.com/atom.xml?redirect=false&start-index=501&max-results=1000
Sitemap: https://mydomain.blogspot.com/atom.xml?redirect=false&start-index=1001&max-results=1500
Thanks
Thanks for explanation !
Sir, I have a blog on blogspot since February 2008 and also having adsense approval named https://astrology-intzaar03.blogspot.com but problem is that even unique articles, they are not ranked in Google search results. Please suggest any free unique blogger template and also amp template.Thanks
Hello,
I need this site for guest posting. I can pay you $10 for each post. I will send you an article soon.
Thanks
Can i use this robots txt to wordpress website too ?
thank you for information
Thank you for your tips but won’t Disallow: /20* section will also disallow post pages indexed?
Because post links also start with date on Blogger. For example:
https://www.example.com/2024/06/example-post.html
And why we keep these lines?
User-agent: Mediapartners-Google
Disallow:
Google says removing these lines from robots.txt:
https://support.google.com/adsense/answer/10532?hl=en
Thank you so much, you save me. I was searching for best robot text file over two days. Now i have find it here. This is the best article on the internet. I have enable it on my blog, https://celways.blogspot.com/ thanks again. lot of blesses
Thank you so much, you save me. I was searching for best robot text file over two days. Now i have find it here. This is the best article on the internet. I have enable it on my blog, thanks again. lot of blesses
I want to fix blogger url cononical like (?m=1) on blogger. If you have any suggetions please write to me!
Thank you so much for this information!
However, can I please ask if I should include the * symbol?
This is exactly as I have pasted it into custom robots text. Mine is a blogger blog but with a custom template:
Thanks in advance. Jan
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search*
Disallow: /20*
Disallow: /feeds*
Allow: /*.html
Sitemap:
Sitemap:
Please provide me suggestion about my roboto.txt.
Please answer me below robot.txt stucture is good for my blogger website:
User-agent: *
Disallow: /search
Disallow: /category/
Disallow: /tag/
Disallow: /*?m=1
Disallow: /*?m=0
Disallow: /cgi-bin/
Allow: /
Sitemap: https://galaxyonknowledge.blogspot.com/sitemap.xml
Sitemap: https://galaxyonknowledge.blogspot.com/sitemap-pages.xml